
PDF 파일은 데이터 행을 복사하여 붙여 넣는 게 어렵다. 특히 텍스트를 써야 하는데 형식을 유지한 채로 가져오는 것은 더욱이 스트레스를 안겨다 준다. 요즘은 PDF 파일이 보편화되어 있고, csv 등으로 출력해보는 것이 인터넷 상으로도 가능하지만,
어느 정도 보안이 필요한 급여 관련된 혹은 주요한 pdf 파일의 경우에는 난감해지는 경우도 생긴다. 엑셀 CSV 파일로 요청해서 받으면 제일 좋겠지만 불가능할 때, 파이썬 코드로 해결해보자
먼저 PDF에 테이블 (표) 형태의 데이터가 필요하다.
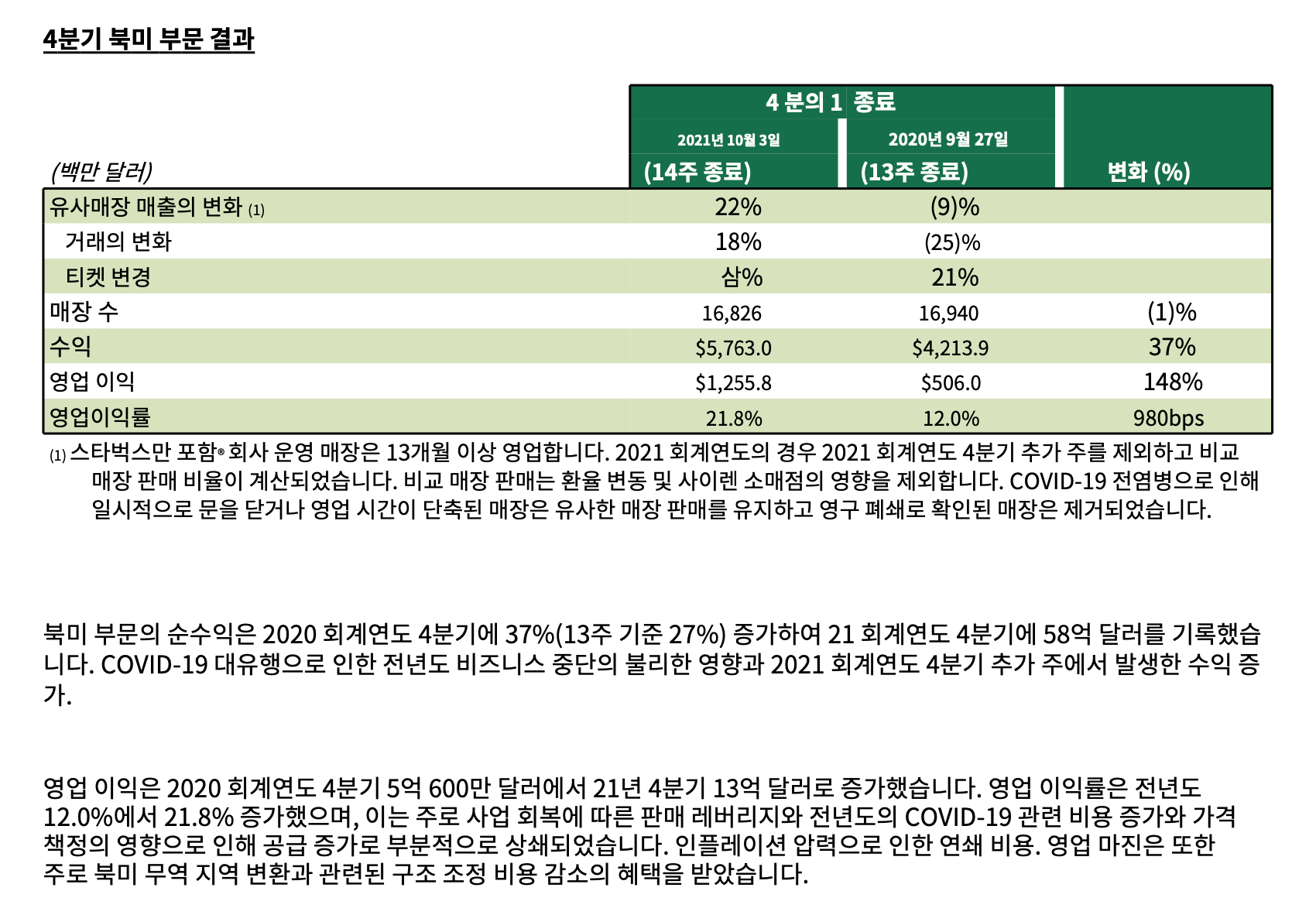
---- 변환결과 ----

스타벅스 분기 매출 자료를 예시로 가져와보면 정확하진 않더라도 잘 가져오는 걸 확인할 수 있다. (구글 번역을 거쳤기 때문에 데이터가 깨진 형태처럼 보이지만) 영문으로 출력해보면 깔끔한 테이블 형태로 보여주는 편
대부분 정렬된 표로 만들어진 데이터가 PDF에 있으면 긁어다 붙여넣기 하기가 너무나 어렵다. 이러한 점을 속 시원하게 해결해주는 라이브러리가 바로 Tabula-py이다.
오늘은 PDF로 제작된 무수히 많은 급상 여명 세서 PDF (100명분!)을 CSV 파일로 버튼 한 번에 폴더 안에 있는 pdf들을 바꿔주는 방법을 배워보자.
* 본 파이썬 코드는 반드시 '자바' 및 tabula 라이브러리 설치가 되어 있어야 정상 작동합니다. (작동 가능 환경 window / mac / ubuntu)
+ tabula 라이브러리 기본 환경은 윈도에 적합합니다.
+ 하지만 윈도우 는 자바 관련 환경변수 설정 난이도가 있음으로 리눅스 환경에서 진행하시면 좋습니다.
+ 제 사용 환경은 파이썬 3.8 (A) / 파이참 / 자바 : jdk 15
Tabula 패키지 설치하기
pip install tabula-py
먼저 타뷸라 패키지를 설치해줍니다. 터미널을 활용하시거나 파이참의 경우 인터프리터에서 추가해주세요. 만약 그냥 tabula로 설치하는 경우에는 다음과 같은 에러 메시지에 직면할 수 있습니다.
AttributeError: module 'tabula' has no attribute 'read_pdf'

패키지 설치가 완료되면 아래 코드를 활용하여 PDF에서 손쉽게 데이터를 추출하여, CSV 파일로 저장할 수 있습니다.
import tabula
# Read pdf into DataFrame
df = tabula.read_pdf("test.pdf", options)
# Read remote pdf into DataFrame
df2 = tabula.read_pdf("https://github.com/tabulapdf/tabula-java/raw/master/src/test/resources/technology/tabula/arabic.pdf")
# convert PDF into CSV
tabula.convert_into("test.pdf", "output.csv", output_format="csv")
# convert all PDFs in a directory
tabula.convert_into_by_batch("input_directory", output_format='csv')타뷸라의 가장 큰 장점은 웹주소 상에 존재하는 PDF 또한 CSV형태로 변환할 수 있다는 것입니다. 본 코드를 실행하게 되면 github상에 업로드된 test pdf를 tabula 패키지에서 읽어 들인 후 (tabul.readpdf) 해당 pdf를 csv로 변환하게 됩니다.
다만, 이 코드의 경우에는 단일 페이지만을 조회하는 코드이며, 실제로 더 많은 페이지를 가져오기 위해서는 output_format과 추가로 pages라는 매개변수를 활용해주어야 합니다.
tabula.convert_into_by_batch("/Users/a/PycharmProjects/A/급여", output_format='csv', pages="all")
저는 급여라는 폴더에 모든 지점의 PDF를 넣은 후, CSV로 변환 이를 구글 드라이브 시트에 업로드하는 전략으로 활용하고 있습니다.
구글 드라이브에 올려두고 나면, 직원들에게 필요한 데이터로 변환해서 주기도 쉬울 뿐만 아니라 재무, 노무 관련 이슈도 발 빠르게 대응할 수 있겠죠.
구글 드라이브에서 문서를 쉽게 정리하는 방법은 제 게시글 구글 스프레드시트 문서정리 쉽게 하기 [1]를 참고해주세요.

PDF에 빼곡히 정리된 데이터를 CSV로 그리고 구글 스프레드시트까지 연동시켰더니 좀 더 깔끔한 데이터 처리를 할 수 있었습니다.
회계 사무소 등에서 기장받은 파일이나, 매월 받는 PDF 종류의 보고서들까지 타뷸라를 한번 익혀두면 쉽게 데이터를 처리할 수 있으니 일석 이조! 물론, 현재 코드만으로는 이러한 형태의 구현이나, 데이터를 알아보기 쉽게 쪼개는 등의 복잡한 작업을 하기 어렵고, 아무래도 PDF를 또 폴더에 옮겨야 하는 귀찮은 도 있지만 대부분의 경우는 위의 코드로 꽤 많은 것들을 해보실 수 있습니다.
한 번 따라 해 보시고 어렵거나 막히시는 부분은 댓글로 질문해주세요~!
구글 스프레드 시트까지 연동하는 파이썬 코드는 다음 포스팅에서 다루도록 하겠습니다 :)
'파이썬 코드 모음집' 카테고리의 다른 글
| Google Colab 으로 구글애널리틱스(GA4) 데이터 가져오기 (0) | 2022.09.07 |
|---|---|
| 파이썬으로 유튜브 영상 크롤링&다운로드 (코드 확인 22.5.26) (0) | 2022.05.26 |
댓글