
편리한 크롤링을 위한 API 사용 이해하기.

API의 개념도.
API의 역할은?
1. API는 서버와 데이터베이스에 대한 출입구 역할을 한다.
: 데이터베이스에는 소중한 정보들이 저장되는데요. 모든 사람들이 이 데이터베이스에 접근할 수 있으면 안 되겠지요. API는 이를 방지하기 위해 여러분이 가진 서버와 데이터베이스에 대한 출입구 역할을 하며, 허용된 사람들에게만 접근성을 부여해줍니다.
2. API는 애플리케이션과 기기가 원활하게 통신할 수 있도록 한다.
: 여기서 애플리케이션이란 우리가 흔히 알고 있는 스마트폰 어플이나 프로그램을 말합니다. API는 애플리케이션과 기기가 데이터를 원활히 주고받을 수 있도록 돕는 역할을 합니다.
3. API는 모든 접속을 표준화한다.
API는 모든 접속을 표준화하기 때문에 기계/ 운영체제 등과 상관없이 누구나 동일한 액세스를 얻을 수 있습니다. 쉽게 말해, API는 범용 플러그처럼 작동한다고 볼 수 있습니다.
API유형은 어떤 게 있을까?
1) private API
: private API는 내부 API로, 회사 개발자가 자체 제품과 서비스를 개선하기 위해 내부적으로 발행합니다. 따라서 제삼자에게 노출되지 않습니다.
2) public API
: public API는 개방형 API로, 모두에게 공개됩니다. 누구나 제한 없이 API를 사용할 수 있는 게 특징입니다.
3) partner API
:partner API는 기업이 데이터 공유에 동의하는 특정인들만 사용할 수 있습니다. 비즈니스 관계에서 사용되는 편이며, 종종 파트너 회사 간에 소프트웨어를 통합하기 위해 사용됩니다.
우리는 네이버 API를 먼저 배워봅시다.
Why? 국내 최대 검색엔진 + 대부분의 데이터를 API형태로 구성.
-> 필요한 토큰을 데이터 요청할 때 함께 전달하면 데이터 출력 (입출력의 간결함)
-> 데이터셋(data set)의 간결함 (빠른 속도 + 대용량 데이터)
-> Python 친화적 (물론 예제는 친화적이지 않음… (우리가 한 번은 배워야 하는 이유)
https://developers.naver.com/main/
개발자 등록하러가기
개발자 등록 방법
https://developers.naver.com/docs/common/openapiguide/appregister.md
네이버 API는 urlib으로 충분히 활용할 수 있습니다.
| import urllib.request client_id = "[자신의 client id]" client_secret = "[자신의 client secret]" #도서검색 API #디폴트(json) https://openapi.naver.com/v1/search/book?query=python&display=3&sort=count #json 방식 https://openapi.naver.com/v1/search/book.json?query=python&display=3&sort=count #xml 방식 https://openapi.naver.com/v1/search/book.xml?query=python&display=3&sort=count url = "https://openapi.naver.com/v1/search/book.json" option = "&display=3&sort=count" query = "?query="+urllib.parse.quote(input("질의:")) url_query = url + query + option #Open API 검색 요청 개체 설정 request = urllib.request.Request(url_query) request.add_header("X-Naver-Client-Id",client_id) request.add_header("X-Naver-Client-Secret",client_secret) #검색 요청 및 처리 response = urllib.request.urlopen(request) rescode = response.getcode() if(rescode == 200): response_body = response.read() print(response_body.decode('utf-8')) else: print("Error code:"+rescode) |
응답 예시
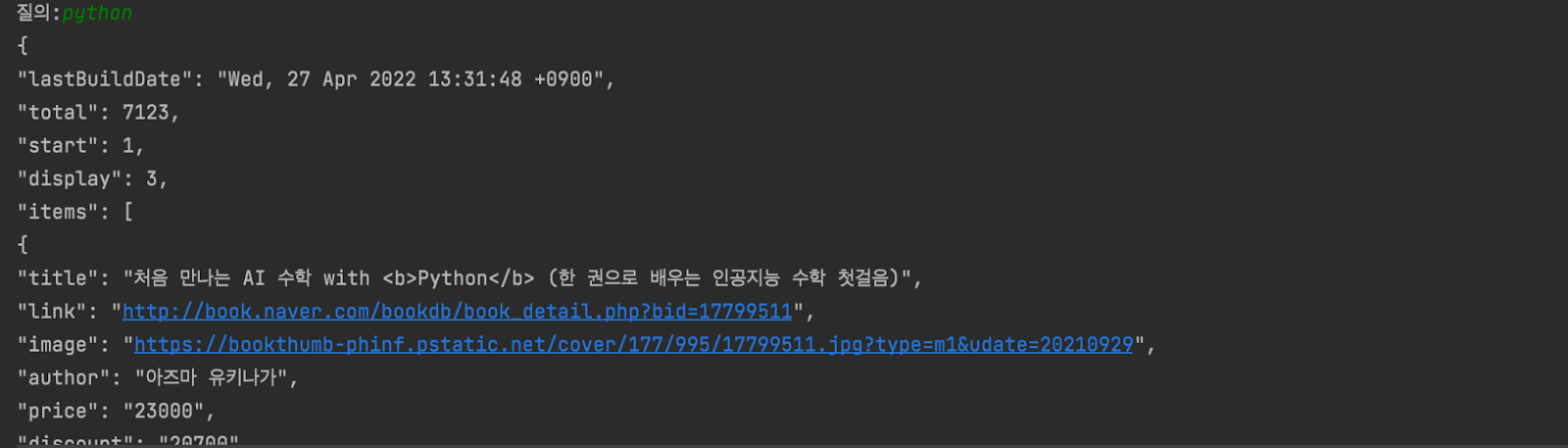
오류 체크하기
SSL 관련 오류 메시지 -> import ssl 추가하기
import ssl
context = ssl._create_unverified_context()
…
response = urllib.request.urlopen(request, context=context)
샘플 코드 2
파이썬 네이버 금융 주식 정보 가져오기 [API이지만 토큰 없이 가져오는 케이스]
| from urllib import parse from ast import literal_eval import requests def get_sise(code, start_time, end_time, time_from='day') : get_param = { 'symbol':code, 'requestType':1, 'startTime':start_time, 'endTime':end_time, 'timeframe':time_from } get_param = parse.urlencode(get_param) url="https://api.finance.naver.com/siseJson.naver?%s"%(get_param) response = requests.get(url) return literal_eval(response.text.strip()) get_sise('005930', '20220426', '20220427', 'day') print(get_sise('005930', '20220426', '20220427', 'day')) |
응답

샘플 코드 3
네이버 검색 API 응용해보기 [요청 url 구조 바꿔보기]
네이버 검색 Open API
https://developers.naver.com/docs/serviceapi/search/blog/blog.md#%EB%B8%94%EB%A1%9C%EA%B7%B8
블로그의 경우 :
3. 요청 변수 부분은 option 란에 바꿔봅니다. ex) display=1
Advanced 연습
출력 데이터 csv로 추출하기
1. pandas 모듈 설치하기
pandas는 Python의 대표적인 데이터 분석 툴로써, 데이터 분석과 관련된 다양한 기능을 제공 pandas를 사용하기 위해서는 다음의 명령어로 설치를 해야 한다.
- pandas 설치: pip install pandas
판다스의 최고 장점은 데이터 프레임으로 엑셀처럼 테이블로 만들어놓고 저장부터 데이터 입출력까지 코드 몇 줄로 가능하다는 점!
| from urllib import request import pandas as pd import ssl #킨덱스에서 상장법인 목록 가져오기 url='http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13' #ssl 에러 피하기 위해 pandas read html 이전에 urllib을 먼저 선행해 유효한 컨텍스트로 https 응답을 처리해줍니다. context = ssl._create_unverified_context() response = request.urlopen(url, context=context) html = response.read() code_df = pd.read_html(html, header=0)[0] code_df = code_df.rename(columns={'회사명': 'name', '종목코드': 'code'}) code_df.head() print(code_df.head()) code_df.to_csv("킨덱스 상장법인.csv", mode="w", utf="utf-8") |
'파이썬 크롤링' 카테고리의 다른 글
| Mac 맥에서 파이썬 파일 자동화 크론탭 (0) | 2022.08.17 |
|---|---|
| 인스타그램 크롤링 2022 개정판 코드 수록. (1) | 2022.07.24 |
| 파이썬 200제_코드샘플 python_src200 (2) | 2022.07.08 |
댓글